This is a blog series about integration using Azure cloud components. The focus will be on how to combine the different tools available in the azure toolbox to build robust, scalable and cost-efficient integrations that might be challenging or expensive to achieve with a single tool.
For the first chapter in this series, I'll show how you can combine logic apps and Azure data factory version 2 in order to import an on-premise CSV file into an on-premise database.
The integration scenario is that it's a big file around 100MB so you can't use logic apps with on-premises data gateway as the limit is (currently) around 30MB. (Also if it's an on-premise to on-premise integration it doesn't make sense loading up such a large file to Azure datacenter and back again).
In order to allow a logic app to interact with an ADF pipeline one currently needs an azure ad application.
(The logic app team is working on an ADF connector so this part of the blog might quite soon be obsolete - part 2)
There will be 3 parts:
1 - Create the Azure data factory pipeline to import an on-premise flat file into an on-premise database.
2 - Create the azure ad application in order to be able to execute the ADF pipeline from a logic app.
Create the power bi on-premises data gateway in order to be able from a logic app to list files in a folder and to delete files.
3 - Create a logic app that does use all our components in 1 - 3 and tie everything together to finalize the integration.
Let's start creating the Azure data factory. I created a
resource group named HybridIntegrations to hold all of the components.
Go to this resource group and click the + button to add an artifact, search for data factory and click create.
Give it a name, choose subscription, resource group (use existing), version v2 (preview) location of your choice (I used west Europe).
Go to the data factory you just created and click the author and monitoring button.
It'll open up another design window. From the rest of part 1, we will work in this design window to create our ADF pipeline.
Per default, you should be in the overview tab of the design window.
On the upper left side from top to bottom you got: a
factory symbol, a
rectangle with 2 squares (this is your current view/tab), a
pencil (this is the actual graphical designer where you can create pipelines and linked services (ie. connections to other systems like file, sftp, SQL, blob storage...)) and a
'watch' / speedometer (where you can get basic execution history and status).
Click on the pencil symbol and when the designer window appears, click the + button and choose pipeline from the drop down. Give it a name in general TAB (csvFileToSQLImport in my case) and define 2 parameters in parameters TAB -> FileName and FileFolder both of type string. We'll use these to make the solution dynamic.
Now expand the 'Data Flow' headline under activities in the designer and drag and drop the Copy activity to the designer blank area. (it's expanded in the image above). We'll now focus on configuring this activity so just click on it.
It's mandatory to configure a source and a sink (as they call the destination, ETL - nomenclature?)
You can give your pipeline a name in general TAB. Then click the source TAB. If this is your first pipeline you won't have any dataset so click the +New button. We'll now basically configure artifacts to pick up the source file.
In the new dataset pane that appears, click the filesystem TAB and choose file system -> finish. You should now have a default named dataset. Give it a meaningful name and click the Connection TAB. You'll presumably not have any linked service so click the + New button and start to configure your new linked service for the file system dataset.
Give it a name, choose the type to be file system and click New in the Connect via integration runtime dropdown.
In the 'Integration runtime setup' pane that appears, choose 'Private network' and next. Give it a name and click next. Finally, click the 'express setup' and follow the instructions. (This will download and install a local integration runtime on the machine you're working on and finally register the runtime in your Azure data factory)
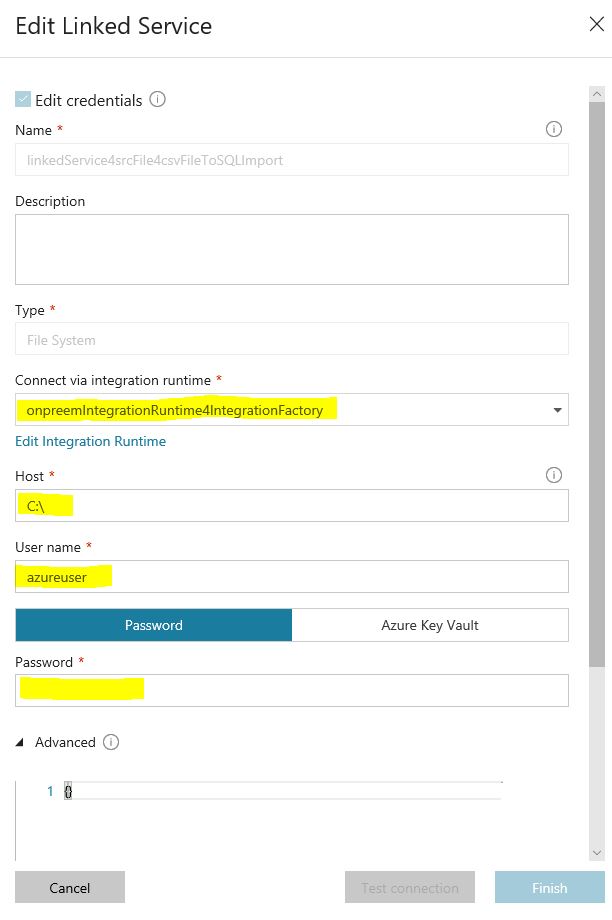
Once your local integration runtime is installed, configured and registered you can go on and finalize your linked service for the file source. You need a user that does have read and list files access to the folder where you want to pick up files. See below for the remaining parameters to fill. On a successful test of your connection click the finish button.
Almost done with the source file dataset configuration. We need to specify folder and file to pick up. You can do this by clicking the browse button and choose a specific folder and file. However, to make this component more reusable we will use the two input parameters to the pipeline that we defined earlier.
So set the folder to
@pipeline().parameters.FileFolder and the filename to @pipeline().parameters.FileName
Additionally, you need to specify the file format. I'm not going into the details here as these settings are standard for flat file parsing, see below.
Almost done ... for the flat file source. Just click the schema TAB and create/define the column names and types for your flat file structure.
Now it's time for the sink (destination) dataset. Click on your pipeline or the pipeline TAB in the designer area. Click on the copy task and on the sink TAB below. Choose new and in the new dataset pane that appears choose databases and SQL server. Click finish.
A new design TAB for the sink (destination) dataset will appear. Give it a name in the general TAB. In the connection TAB, click the new linked service button and fill in the values according to your local SQL server installation/database and target table where you want the flat file values to be inserted. (you should now be able to choose the same local integration runtime as you used for the file source linked service)
Once you have connectivity to your SQL connection click finish and choose target table.
In the schema TAB, you can autogenerate the schema for your target table.
We're done ... with the destination connection (the sink).
Just one last thing before we can test this pipeline, let's define the mapping between the source schema and target schema. Click on your pipeline component or the design TAB for your pipeline. Then choose the Mapping TAB and click the import schema button.
Based on your schema names for source and target the designer will try to automap source column names to target column names. You then have the choice to adjust the target columns by choosing items in a drop-down list. (Notice that I had to remove some target columns from the target schema so that source columns matched exactly the number of target columns. Otherwise, the 'mapping' failed even though I unchecked the target columns in my database that had default values)
(This is not much for the T in an ETL engine. (Transform) And it will limit, quite a lot, the real world scenarios that can be handled by the copy task. It's, of course, possible to do custom transformations, but from what I've read so far, it involves spinning up some cloud servers running the transformation processing cycles on Azure virtual machines and as soon as you got VMs involved, your costs are going to run away. But there are ways around this that can be used now. For instance, one can upload the source dataset to a blob and use a function to do the transformation)
We should now be able to test our pipeline and finalize part 1.
Normally you would create a trigger and define an import schedule for the file. To do this you just click the trigger button and choose new/edit. Then follow the steps to define your trigger.
For simplicity, we'll debug our pipeline by clicking the Debug button with the play symbol and enter our custom parameters as below.
If everything goes well you should have some new records in your database table.
Finally, let's do a load test to make sure that this ETL engine delivers. To do this I just added an 'ItemDesciption' column to boost data size in one record and I created a file with a million record. (250 MB). I thought that I would have to wait for some minutes but to my surprise after only 30 seconds the pipeline execution was complete and the records were inserted.
Great but what if you want to delete the source file? Well, it's not really doable out of the box in the designer (at least I haven't figured it out). Googling it will point you to using azure batch services, which involves virtual machines and that means rising costs as I pointed out earlier... However, there's another way to do it that I'll show you in the next 2 parts/post.