(Recently Microsoft released connectors to create and get pipeline runs from a logic app so we don't have to use the azure ad app that we created in part 2)
You can access the previous parts here:
Part 1
Part 2
We'll create a new logic app in the resource group where our azure data factory resides (in my case it's in the hybrid integrations resource group) - (it doesn't have to be in the same resource group, it's just convenient)
- Go to the resource group
- click the + add button
- search for logic app
- fill in the details as below

- click the create button
- once the logic app is created you might get a popup window where you can choose 'go to resource' (otherwise just locate your newly created logic app and click edit)
- you should have a selection of templates to choose between. I usually start with the http request response template. (easy to pass in parameters and easy to trigger from different clients)

We first want to list files in the folder from where the Azure data factory pipeline import file data to SQL server table (see Part 1). To do this we'll use the file connector action 'list files'.
- In the logic app designer add an action below the HTTP request trigger.
- In the search field type 'file system', be patient and then the file system connector appear choose the 'list files in folder' action.

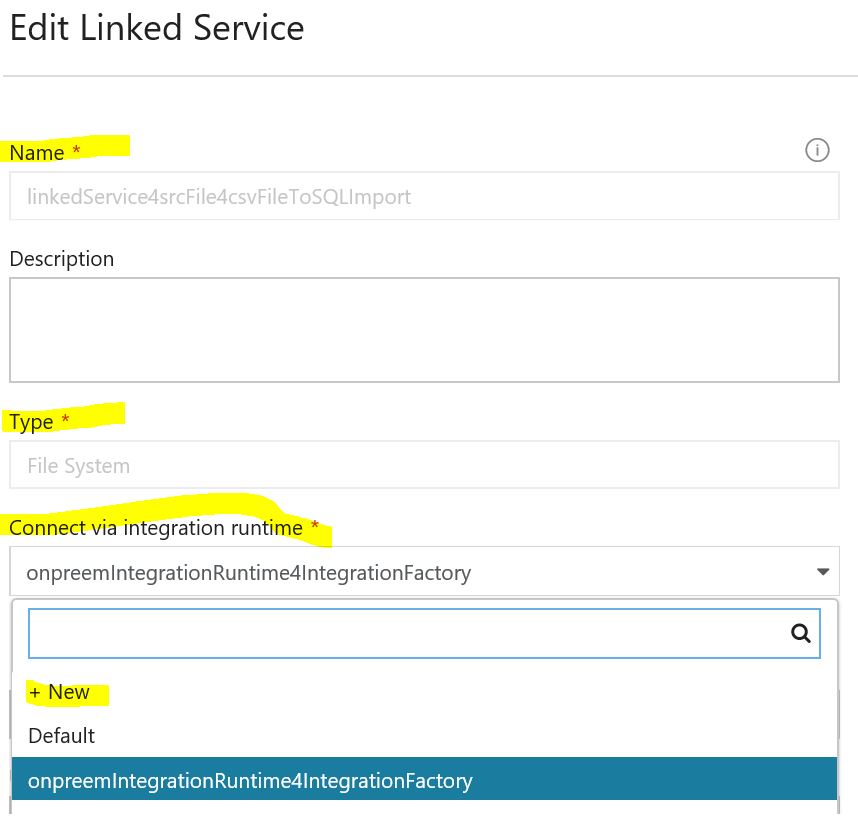
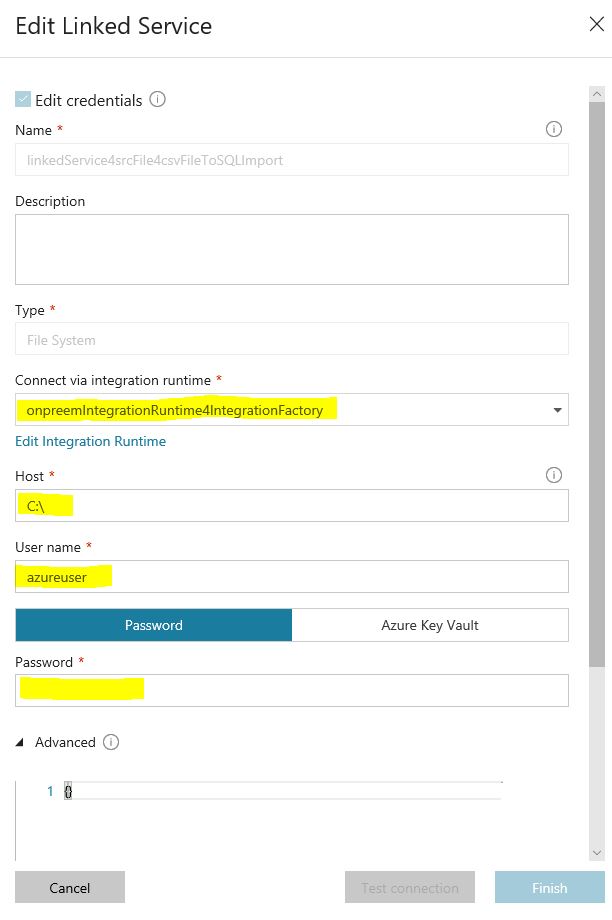
You'll then need to define your connection to your local file system. It needs to know the UNC root folder, credentials to use (don't forget to prefix the username with the domain) and the gateway to use.

Once the connection to your local file system is successfully created you just need to choose the folder where to list files. (in my case it's the same as the root folder so just a front slash)

Now it's time to trigger the Azure data factory pipeline. We'll use the Azure data factory connector to do this. Add a new action below the list file action. Then search for 'Azure data factory', be patient and then the connector actions are displayed choose the 'create a pipeline' run action.

You'll then be asked to sign in to your subscription and when to configure your action as below.

Quite self-explanatory but where do I put the pipeline parameters? As the ADF connector is quite new I think this is just a miss from the product team and it'll soon be corrected but actually, in the 'code view' of your logic app workflow, you can pass in parameters to the pipeline as is shown below.

Under the 'inputs' section of the 'create a pipeline run' JSON definition you can add a 'body' structure that contains the parameters to you ADF pipeline. Hopefully, in the future, you can just do this in the designer pane.
For now, we'll not use the output of the list files action and just use a static filename. Save the logic app and run it. If everything goes well it should trigger your ADF pipeline and import the specified on-premise file data to the on-premise SQL server table.
Next, we'll improve this solution so it's more production like. The filename will be passed as a parameter to the Azure pipeline run action, we will handle multiple files and delete the files once successfully imported to the database.
Let's start by making our call to trigger a pipeline run more dynamic. Below the 'create a pipeline run' action add a foreach loop and configure its input to be the 'body' output of the list action. Also move the 'create pipeline run' inside the foreach loop.

We need to set the filename dynamically to the output filename we get from the list files action.
- Switch to code view (might not be needed in the near future) and replace the static FileName parameter as shown below.

We could just delete the file after the 'create a pipeline run' action but we'll not do this since we can't be sure that the import does succeed. Instead, we'll wait until the pipeline run is successful and then delete the file. To do this we need a do until loop and the 'get a pipeline run' action. We also need a variable with the pipeline run status.
- Below the HTTP request trigger add an action to initialize a new variable of type string.
- Below the 'create a pipeline run' action inside the foreach loop add an action to set the variable to an initial state (so we can handle multiple files)
- Finally, add a do until loop (configuration will follow)

- In the do until loop add an action to 'get a pipeline run'. (you can pick the runid dynamically from the 'create a pipeline run' action)

- Configure the do until loop as shown below and add a 'delay' action (10 seconds delay) and a 'set variable action' below the 'get a pipeline run' action. Set the variable to the Status field that you'll get dynamically from the 'get a pipeline run' action.

- Finally, add a 'delete file' action below the do until loop and set the file field to the 'path' variable you'll get dynamically from the 'list file' action.

Now we have a solution where we're able to import an arbitrary number of files and remove the file once successfully processed. (Some minor modifications should be done before going to production. One would need to handle the case then the import to the database does fail. I.e the do until loop times out or returns an error code. So some conditions should be added to the workflow with relevant actions taken in case of failure)
Otherwise, we could now test the happy scenario of importing two files to our database table just by triggering this logic app manually and check the logging. Below is how my final design looks like and a successful run of two imported files.

This is one simple example of how to use a logic app in combination with Azure data factory v2.